2025-12-26_演進中的計算記憶體層次結構
演進中的計算記憶體層次結構
☘️ Article
- 去年 Groq LPU 要狠幹四方的說法出來時,對岸就在炒所謂的 SRAM 概念股
- 這有點硬要,SRAM 現在居多是整合進邏輯製程內 on-chip 由 TSM 這類公司生產。
- 再來是要價不菲,單位面積存儲容量少的關係,較難有什麼積極擴大應用
- 而物聯網穿戴裝置使用的 PSRAM,本質是 DRAM,介面類似但是不同東西,故稱 pseudo
- 不過有討論,即便部分差錯,還是有可能會把市場的目光帶向 edge computing memory 的應用就是了
- (望向 AI PC 冤魂)
✍️ Abstract
LPU (Language Processing Unit)
LPU 與 SRAM 關聯
- LPU 最大特點:捨棄外部高頻寬記憶體 (HBM),將 SRAM 直接鋪滿晶,使其存取速度與邏輯運算速度幾乎同步,達到極高的傳輸頻寬 (Bandwidth)。
- 使用超大容量的片上記憶體 (On-chip SRAM)。
- LPU 所需的 SRAM 是與邏輯電路一同在先進製程 (如 TSMC) 中製造的,屬於 Global Memory 的一部分,而非外部採購的獨立記憶體顆粒。
- 目前的 SRAM 多由台積電等代工廠直接整合在邏輯製程中,由於單位面積的儲存容量較少且價格高昂,難以在邏輯晶片以外獨立大規模擴大應用。
LPU 的技術優勢
- 由於資料全在 SRAM 內流動,LPU 展現出極致的 Token 生成速度,特別適合需要即時回應的對話型 AI 應用。
- 密度挑戰:SRAM 儲存密度 << DRAM。
- Groq 的單張加速卡僅擁有約 230MB 的記憶體,運行一個 Llama 3 70B 參數等級的模型,需要串聯數百張卡才能容納。
- 部署成本:LPU 在大規模佈署時的機櫃密度與電力成本效益,與 NVIDIA H100 等使用 HBM 的 GPU 相比,存在巨大的物理權衡挑戰。
中國市場炒作現象
- 供應鏈邏輯:LPU 興起主要利好擁有 先進製程、封裝 能力的晶圓代工廠 (Foundry),而非傳統分離式 SRAM 供應商。
- PSRAM (Pseudo RAM):常被應用於穿戴裝置,鎖定低成本 IoT 場景,與 LPU 追求的極致效能不同
- PSRAM 本質是 DRAM。
- 雖然硬體架構不同,但 LPU 帶起的 Edge Computing 討論是有價值的,未來的邊緣 AI 晶片可能會借鑑類似「存算一體」的概念,在特定的低參數量模型上,增加 On-chip Memory 的比例以換取低延遲。
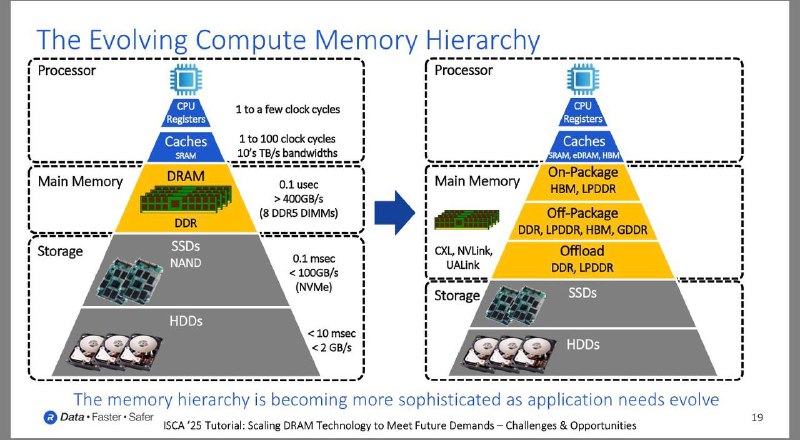
記憶體層次結構
記憶體層次結構的分類與演變
- 處理器層級:傳統上由 CPU 暫存器與 SRAM 快取組成,演進後快取部分開始整合 eDRAM 與 HBM 以提升效能。
- 主記憶體層級:從單一的 DDR DRAM 轉向多元配置
- 封裝內記憶體:HBM、LPDDR
- 封裝外記憶體:DDR、GDDR
- 特定卸載用途的記憶體。
- 連結技術演進:現代架構引入 CXL、NVLink 與 UALink 等高速連結協議,優化記憶體、加速器與儲存裝置間的溝通效率。
- 儲存層級:包含 SSD 與 HDD,雖然存取速度相對較慢,但透過新型互連技術正與運算層產生更深層的互動。
專有名詞
- SRAM (靜態隨機存取記憶體):利用電晶體儲存位元資料,不需要定期重新充電刷新的記憶體,速度極快但成本高且物理佔用面積大,通常作為處理器快取。
- HBM (高頻寬記憶體):一種基於 3D 堆疊技術的高效能 DRAM,透過矽穿孔技術實現極高的資料傳輸頻寬,常封裝在處理器旁以縮短傳輸距離。
- CXL (快速計算鏈路):一種基於 PCIe 介面的開放互連標準,主要用於資料中心,目的是讓處理器、加速器與記憶體池之間共享資源並維持快取一致性。
- PSRAM (偽靜態隨機存取記憶體):內部記憶單元採用 DRAM 結構,但外部控制介面與 SRAM 相似,具備比 SRAM 更高的容量密度與比傳統 DRAM 更簡單的控制介面。
- eDRAM (嵌入式動態隨機存取記憶體):將 DRAM 直接整合在處理器晶片或其封裝中,藉此提供比一般快取更大容量的緩衝空間。