2026-01-08_NVIDIA-BlueField-4-驅動的-ICMS-平台
| # Nvidia BlueField-4 驅動的推論上下文記憶體儲存 (ICMS) 平台 |
|---|
☘️ Article
✍️ Abstract
NVIDIA BlueField-4 驅動 ICMS 平台發布
- 發布概況:NVIDIA 於 2026/01/06 推出推論上下文記憶體儲存 (Inference Context Memory Storage, ICMS) 平台,專攻下一代 AI 領域。
- 解決痛點:解決 代理人 AI、長上下文工作負載 的擴展挑戰,突破數百萬 Token 下的 KV 快取瓶頸。
- 架構革新:作為 NVIDIA Rubin 平台的 G3.5 記憶體層級,填補 HBM (G1)、通用儲存 (G4) 之間的缺口,引入 pod 級架構並整合 GPU、Spectrum-X 乙太網路、儲存裝置,其核心在於由 BlueField-4 驅動的推論上下文記憶體儲存 (ICMS)。
- 硬體基礎:由 NVIDIA BlueField-4 DPU 驅動的快閃記憶體層,專為十億級瞬時 KV 快取設計。
技術規格與效能優勢
- 硬體配置:搭載 800 Gb/s 連接能力、64 核心 NVIDIA Grace CPU、高頻寬 LPDDR 記憶體。
- 容量規模:提供 PB 級共享容量,支援跨節點高速存取。
- 生成效能:相較於傳統儲存方案,每秒 Token 生成數 (TPS) +500% (5 倍)。
- 成本效益:能源效率 +500% (5 倍),顯著降低總體擁有成本 (TCO)。
系統架構與軟體生態
- 連接技術:整合 NVIDIA Spectrum-X 乙太網路,透過 RDMA 確保大規模 AI 工廠的低延遲與資料一致性。
- 軟體協作:利用 DOCA、Dynamo、NIXL 框架,優化 KV 區塊在記憶體階層中的預取與調度。
- 應用價值:協助規劃 GPU 容量,消除儲存瓶頸並支援複雜代理人工作流程。
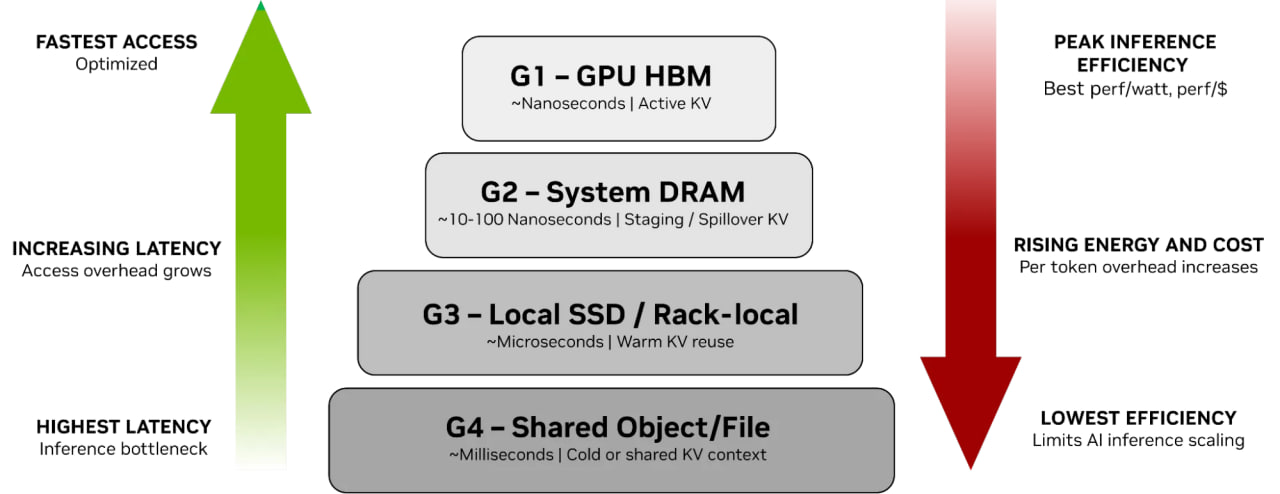
KV 快取記憶體階層 (KV Cache Memory Hierarchy)
- G1 到 G4 是指 KV Cache 所存放的記憶體與儲存階層 (Memory and Storage Hierarchy)。
- 這個分類是用來區分 KV Cache 資料存放在硬體上的位置,依據的是存取速度 (Latency) 與 資料熱度 (Hot/Cold):
- G1 (GPU HBM)
- 用於存放最頻繁使用的資料 (Hot Data)。
- 這是最頂層的分類,直接參與運算。
- G2 (System RAM)
- 用於存放溢出 (Spill) 的資料。
- 當 GPU 記憶體不足時,暫存於此。
- G3 (Local SSDs)
- 用於存放溫資料 (Warm Data)。
- 屬於本地端的儲存空間。
- G4 (Shared Storage)
- 用於存放冷資料 (Cold Data) 與歷史紀錄。
- 這是最底層的分類,通常是傳統的網路儲存系統。
專有名詞
- BlueField-4:NVIDIA 開發的第四代資料處理器 (DPU),整合高效能 Grace CPU 核心與網路加速引擎,專為資料中心處理複雜的資料搬運與運算工作。
- ICMS (Inference Context Memory Storage):推論上下文記憶體儲存,一種為 AI 推論設計的原生儲存基礎設施,優化了 KV 快取的存取與管理。
- KV Cache (Key-Value Cache):鍵值快取,大型語言模型在生成文本時,將先前 Token 的計算中間值儲存起來,以避免在處理長文本時進行重複的矩陣運算。
- Rubin Platform:NVIDIA 推出的 AI 平台,包含新架構的 GPU 與整合式網路、儲存解決方案,旨在支撐兆級參數模型的訓練與推論。
- Spectrum-X Ethernet:NVIDIA 專為 AI 最佳化的乙太網路平台,具備低延遲、高頻寬特性,並透過 RoCE 技術提供可預測的網路效能。
- RDMA (Remote Direct Memory Access):遠端直接記憶體存取,一種允許伺服器直接從另一台伺服器的記憶體中讀寫資料,而無需經過雙方處理器運算的技術,能大幅降低資料傳輸延遲。
- Agentic AI:代理型人工智慧,指能夠自主思考、規劃任務序列並使用工具來達成複雜目標的 AI 系統,這類系統通常需要維護長期的工作記憶或上下文。
- HBM (High Bandwidth Memory):高頻寬記憶體,一種封裝在 GPU 內部的垂直堆疊記憶體,提供極高的資料存取速度。
- DOCA:NVIDIA 的資料中心基礎設施軟體框架,開發者可以利用此框架編寫程式以充分發揮 DPU 的硬體加速功能。
- NIXL (NVIDIA Inference Transfer Library):NVIDIA 推論傳輸庫,用於協調推論上下文在各個記憶體與儲存層級之間移動的軟體組件。
- TCO (Total Cost of Ownership):總體擁有成本,指購買設備以及在其生命週期內運行、維護、電力消耗等所有成本的總和。