2026-03-25_GOOGL_TurboQuant提升長文本處理效率的極致壓縮技術
TurboQuant Google 提升長文本處理效率的極致壓縮技術
☘️ Article
癌大觀點
- Google 的新壓縮技術說可以省 kv memory size 達 6x
- kv cache 主要常駐在 gpu 的 hbm/gddr,gpu 撐不住就 offload 到 cpu ram,再更大的 context 或冷資料才有機會跑到 ssd
- 然後現在市場把 nand 股票也一起配合新聞丟下去,這就是近期市場很可愛的地方,一言不和整包撞下去
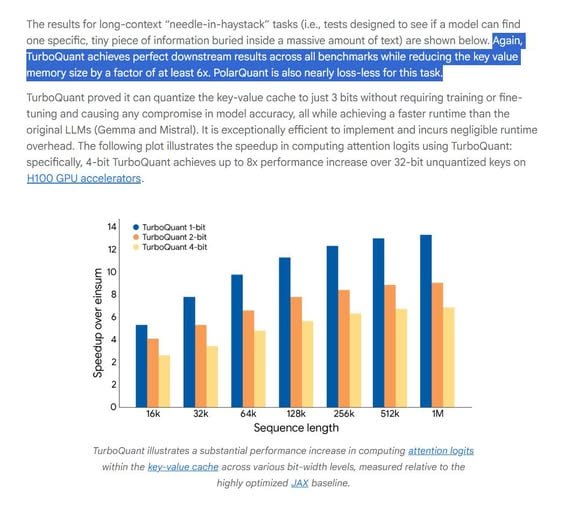
- "TurboQuant 是一種壓縮方法,能在完全不損失準確度的情況下大幅縮小模型大小,非常適合用來支援鍵值 (Key-Value, KV) 快取壓縮和向量搜尋 (vector search)。
- 它透過兩個關鍵步驟達成這項效果:
- 高品質壓縮 (PolarQuant 方法):
- TurboQuant 首先會隨機旋轉資料向量。這個巧妙的步驟能讓資料的幾何結構變得更簡單,進而可以更輕鬆地對向量的每個部分分別應用標準且高品質的 量化器 (quantizer)。
- 量化器是一種工具,能將大量連續的數值 (例如非常精確的小數) 對應到較小的離散符號或整數集合 (例如在音訊量化或 JPEG 壓縮中所使用的方式)。
- 在這個階段,系統會使用主要的壓縮能力 (大部分的 bit) 來捕捉原始向量的主要概念與強度。
- 消除隱藏誤差:
- TurboQuant 接著利用極小的一部分壓縮能力 (僅 1 個 bit),將 QJL 演算法 應用於第一階段後留下的極小誤差部分。
- QJL 階段相當於一個數學的誤差校正器,能消除偏差,讓最終的注意力分數 (attention score) 更加準確。"
- 高品質壓縮 (PolarQuant 方法):
- https://research.google/blog/turboquant-redefining-ai-efficiency-with-extreme-compression/
✍️ Abstract
TurboQuant
定義
- 技術定義:Google 研發的極致壓縮技術,在不損失準確度下大幅縮小模型體積。
- 核心應用:支援 KV (Key-Value) 快取壓縮、向量搜尋 (Vector Search)。
- 兩個關鍵步驟:
- 高品質壓縮:運用 PolarQuant 方法,隨機旋轉資料向量以簡化幾何結構,並透過標準量化器捕捉主要概念與強度。
- 量化器 (Quantizer) 功能:將大量連續數值對應至較小離散符號/整數集合,如:音訊量化、JPEG 壓縮。
- 消除隱藏誤差:使用 極小壓縮能力、QJL 演算法 作為數學誤差校正器,消除首階段偏差以提升注意力分數準確度。
- 高品質壓縮:運用 PolarQuant 方法,隨機旋轉資料向量以簡化幾何結構,並透過標準量化器捕捉主要概念與強度。
癌大觀點
- 效能指標:Google 新技術宣稱可節省 KV (Key-Value) 記憶體體積達 6 倍。
- 儲存層級:KV Cache 主要常駐於 GPU 的 HBM (High Bandwidth Memory)/GDDR
- 滿載則卸載至 CPU RAM,更大/冷資料 才進 SSD。。
- 市場觀察:市場隨新聞拋售 NAND 相關股票,反映投資情緒容易一言不合整包撞下去。
專有名詞
- KV Cache:鍵值快取,模型運算時主要常駐於圖形處理器記憶體的資料,滿載時會卸載至系統記憶體或固態硬碟。
- HBM、GDDR:圖形處理器的高頻寬記憶體,為鍵值快取最優先常駐的硬體位置。
- NAND:快閃記憶體,固態硬碟的儲存元件,市場因預期儲存需求降低而拋售相關股票。
- PolarQuant:高品質壓縮方法,透過隨機旋轉資料向量簡化幾何結構,以利後續量化處理。
- 量化器:數值轉換工具,將大量連續精確數值對應到較小的離散符號或整數集合。
- QJL 演算法:數學誤差校正器,利用單一位元的極小壓縮能力,消除首階段壓縮留下的偏差。
- 注意力分數:模型運算指標,經過誤差校正階段後能確保最終結果維持高度準確性。